Blog &
Articles
Retrieval Roulette: Why Mission-Critical AI Systems Need More Than Search
")
Imagine if a hospital told a young medical student “We want you to perform surgery on a patient, but you are forbidden to read any medical textbooks or reference materials. You can only do Google searches during the operation, and you’ll have to trust whatever the top ten results show you.”
You’d think they were crazy, right?
And yet, that’s essentially the approach organizations take when they upload PDFs and other documents as a source of knowledge for their AI systems: effectively applying a Google-circa-2004 approach to information retrieval. The AI can’t read the whole manual. It can only search for fragments and hope the algorithm surfaces everything important.
So what can go wrong with the old-school Google method – and, more importantly, what’s the alternative?
Easy Answers: The Seductive Simplicity of ‘Talk to Your PDF’

The first time you upload a research paper into ChatGPT and ask “What does this say about X?” then get a coherent answer… It feels like magic. And for individual knowledge workers doing research, exploring ideas, or getting up to speed on unfamiliar topics, this capability is genuinely transformative. It’s also given rise to countless “talk to a PDF” chatbots that let users query a company’s policies or a consultant’s book.
And honestly? For low stakes situations where errors wouldn’t be catastrophic and people are treating the chatbot as just one information source out of many – these solutions work pretty well.
But there’s a massive gap between ‘useful for ad-hoc Q&A on personal projects’ and ‘reliable enough to deploy across an enterprise making consequential decisions’ – where even a 5% error rate = hundreds of costly mistakes per week.
Playing Darts with Documents: The Limits of Traditional RAG

Before anyone accuses me of misrepresenting the tried-and-true approach of Retrieval Augmented Generation (RAG), let’s take a moment to review exactly what happens when you upload a file attachment in a general-purpose chatbot, and why that might create issues in cases where completeness and accuracy are mission-critical.
Imagine if, when you upload a file attachment into your favorite AI chatbot, the system copied all its contents to index cards, then arranged those index cards on a giant dartboard.
Then, when a user asks a question, the retrieval algorithm throws N darts (maybe 5, maybe 10, maybe 20) which are mathematically attracted to the index cards containing whatever words and phrases seem most strongly related to the words and phrases in the user’s query.
Sometimes you get lucky, and the index cards you hit contain all the pertinent information you need…. But sometimes you don’t.
There’s a famous scene in the movie Raiders of the Lost Ark where a Nazis spy grabs a medallion with a treasure map out of a fire, and – just before he drops it – the map gets burned into his hand. Afterwards, the Nazis go looking for the treasure, referencing the scars, but without realizing there was more information on the other side of the medallion. As a result, the Nazis end up digging in the wrong place.
That’s effectively what can happen if you rely solely on chunked retrieval for operational guidance. And here’s the insidious part: RAG errors don’t look like errors. If the RAG results contain some but not all of the relevant information in the source documents the AI model doesn’t say “I might be missing something,” because it has no idea to believe it missed anything. Instead it just… confidently presents whatever it retrieved as if it’s the complete story.
So you might get 8 out of 12 key compliance requirements and never know the other 4 exist. Or you might get a medication protocol that omits the contraindication for patients with renal failure because that warning happened to fall in chunk 47 and the algorithm only surfaced chunks 12, 23, and 38.

An admittedly oversimplified example of the risks of RAG
Our own team learned these limitations of traditional RAG the hard way. Early in our work with AI, clients came to us asking to have AI agents reference massive government regulatory documents and corporate policies, while demanding “no errors” and “zero hallucinations.” One organization we spoke to – a large provincial health ministry – had been experimenting with traditional RAG approaches, internally, and couldn’t achieve better than 90 to 95% accuracy on clinical guidance queries, which sounds good until you realize that’s one error in every ten to twenty patient interactions.
In these cases, we obligingly spent weeks sifting through those documents rearranging, reformatting, and meta-tagging the contents and optimizing the number and size of chunks returned. And this approach worked… sort of. We passed all the benchmark tests and never had a client call us screaming that our AI had given dangerous advice. But, between reformatting documents and QA testing, the amount of effort required to make RAG reliable was staggering. Eventually, we threw up our hands and asked: “Why are we working so hard forcing RAG to do something it really wasn’t designed to do?”
Stacking the Deck: Improving Results Through Module-Level Retrieval

Google – the company that literally invented modern semantic search – has long recognized that, for certain queries (“Who directed The Godfather?” or “What time does the pharmacy close?”) you don’t want users wading through search results. You want structured, complete, reliable information presented in a predictable format: hence those “Knowledge Panels” that appear at the top of certain searches – like your favorite restaurant or sports team – with information pulled from structured data sources rather than searches.
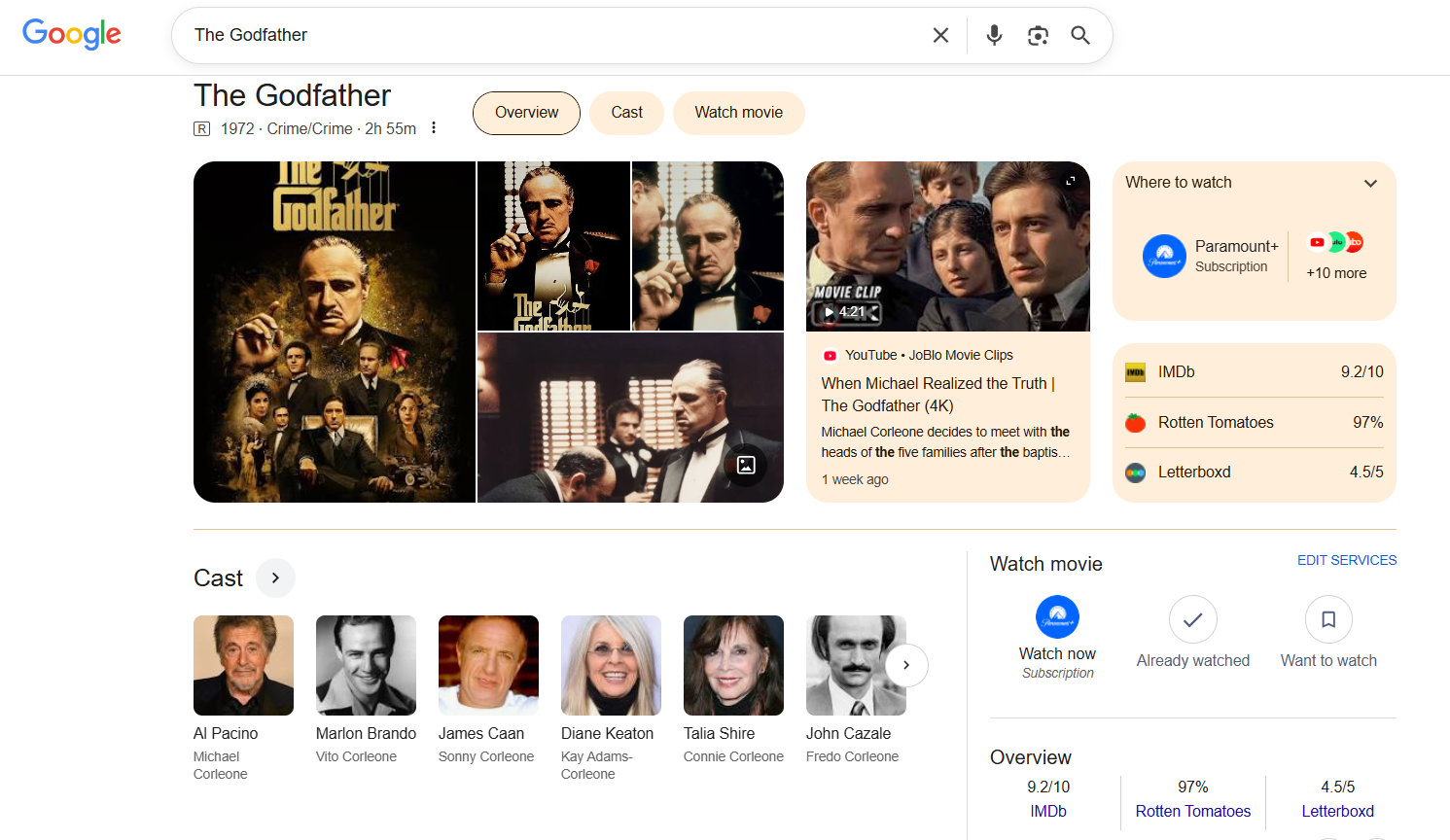
Our company quickly came to the same realization about using semantic search to inform AI responses, which led us to develop a system for “module-level retrieval”. Instead of chunking documents and hoping semantic search surfaces the right fragments, we created a curated knowledge base with complete, self-contained modules on major topics, with a tiered table of contents the AI agent can summon on command.
For example, when we built an AI agent to assist housing inspectors, we had one module on electrical systems, one on plumbing, one on heating / ventilation / air conditioning, plus modular subsections. Then, when the agent needs to find information on electrical wiring, it doesn’t retrieve chunks 12, 23, and 38 from a 200-page PDF of the local building code. Instead it loads the entire electrical systems module, with all the steps, all the warnings, all the edge cases, and all the caveats.

The AI model still does the work of synthesizing that information into a helpful response, and while there is always a small chance it might connect the dots incorrectly and “hallucinate” an incorrect response (the same way even an experienced human worker might misremember or misstate something), the fact that it has the complete source material (not fragments that may or may not contain the critical details) might drive that possibility down to less than 1% – depending on how well the modules were organized and labeled to begin with.
The House Always Wins: Why Component Content Management Systems Beat Document Folders

“Component Content Management System” isn’t a type of software most people are familiar with, unless you’ve worked for a textbook publisher, an enterprise software provider, or in the documentation department of a German engineering conglomerate (all of which I’ve done at various points.)
Simply put, a CCMS lets you create documents from short, reusable snippets: for example, imagine a furniture company having one content module with the instructions for how to wash a certain type of fabric, and when they change that module it updates the documentation for every product that uses that type of fabric.
Now, before you fall asleep or put on your “TL;DR” blinders, stay with me, because a CCMA is where the real leverage happens with organizational knowledge + AI.
Without a CCMS, you’re stuck with what most organizations have: monolithic documents scattered across SharePoint / Google Drive, and various departmental file servers. The electrical safety procedure exists in 14 different versions across 8 different documents. Nobody’s quite sure which one is current. When you need to update the voltage testing requirements, you’re playing whack-a-mole trying to find every instance.
Now imagine instead that your organizational knowledge lives in discrete, versioned, reusable components. The electrical safety procedure isn’t buried in a 200-page PDF – it’s a standalone module. The voltage testing requirements aren’t copy-pasted into 14 documents – they’re a single component that gets referenced wherever needed.
When you update the voltage testing requirements, you update one component. Every procedure that references it automatically reflects the change. There’s no version drift, no contradictory guidance, no wondering if you caught them all.
And here’s the kicker: once your content is structured this way, module-level retrieval becomes almost trivial. If you connect an AI agent with module-level retrieval capability to a CCMS, the agent doesn’t need to search through 200 pages hoping to find the right chunks. It just loads the “Electrical Safety – Voltage Testing” module. Complete. Current. Correct.
Not all CCMS platforms are equivalent here. While some store data as loose snippets, you ideally want a system that maintains hierarchical structure (using established standards like DocBook XML), making it easier for AI agents to drill down from document to section to specific topic. We’ve had particular success with Paligo – a component CMS that we previously deployed with clients in the insurance industry for traditional documentation projects. Having content structured in this way made it much easier to map content to our AI platform’s module-level retrieval system (via an API query) than having to recreate policy PDF policy documents inside the module-level retrieval system, as we’ve done on other projects..
Dealer’s Choice: Selecting the Right Retrieval Approach

Module-level retrieval has tradeoffs compared to search-driven RAG:
- It requires more upfront work to structure content into modules.
- It requires judgment about what constitutes a “complete” unit of knowledge.
- It doesn’t scale infinitely the way “just upload everything from our SharePoint site and let the algorithm sort it out” does.
And it’s not better than traditional RAG in all cases: we still have AI agents search chunked RAG documents (hosted in Vectara) for questions that cross multiple modules or require discovery across large document sets – things like ‘What are all the instances where our product documentation mentions European Union safety regulations?’ or ‘Show me every procedure that references confined space entry.’ For those queries, semantic search is exactly the right tool.
But if you want an AI agent providing operational guidance in areas people need to get right every single time, then you can’t afford to play retrieval roulette and hope the algorithm surfaces everything important.
For instance, when a compliance officer is researching AML regulations to build a training program, a 90% complete answer might be a reasonable starting point for further investigation. When that same compliance officer is advising a colleague on whether a specific transaction needs to be reported, a 90% complete answer might mean missing the red flag that triggers a regulatory violation.
Of course like most things traditional RAG versus module-level retrieval isn’t an either / or: it’s entirely possible to make your knowledge base searchable, or even use semantic search within modules for use cases requiring extremely fine grained retrieval results.
Conclusion
Information retrieval and content management aren’t the kind of thing that gets breathless coverage in tech blogs. But it’s the “boring” foundation that makes all the exciting things your organization might want to do with AI possible.
The question here isn’t whether module-level retrieval is “better” than traditional RAG. It’s whether you’re using the right tool for the job.
For individual knowledge workers doing research or exploring ideas, doing a quick file upload then relying on chunked RAG with semantic search is a powerful tool. But for mission-critical operational guidance, where incomplete information can mean compliance violations, safety incidents, or financial losses, module-level retrieval backed by structured content isn’t optional. It’s the foundation that makes AI systems trustworthy enough to deploy.
After all, if even Google knows when to use structured knowledge instead of search, maybe we should too.


Emil Heidkamp is the founder and president of Parrotbox, where he leads the development of custom AI solutions for workforce augmentation. He can be reached at emil.heidkamp@parrotbox.ai.
Weston P. Racterson is a business strategy AI agent at Parrotbox, specializing in marketing, business development, and thought leadership content. Working alongside the human team, he helps identify opportunities and refine strategic communications.




